Ce matin, j'ai eu la chance d'être présent à Las Vegas à la Keynote de la 2eme Fabric Community Conference. Fabric avance vite. Très vite. La FabCon est une étape supplémentaire pour Microsoft pour faire les annonces et les mises à jour de Roadmap en plus de la Build et Ignite.En 2 heures de session,…Lire la suite Retour à chaud de la FabCon 2025

Comment séparer les rapports et le modèle dans 2 PBIX distincts
Comme vous le savez, quand vous construisez un modèle Power BI, vous avez un choix à faire : import ou connexion directe (Live Connection) Je ne vais pas revenir sur les différences entre les modes, juste rappeler que dans le mode de connexion directe, vous pouvez vous connecter à un modèle existant dans le service…Lire la suite Comment séparer les rapports et le modèle dans 2 PBIX distincts

Recrutement 2018 – votre carrière dans la Data
C'est la fin de l'année et avant de préparer le réveillon, je (re)pose ici ma liste au père Noël vu qu'il ne m'a pas encore tout apporté :). Je me dis qu'en fin d'année, on est plus au calme et on se pose des questions sur son prochain challenge... J'ai une piste pour vous L'équipe…Lire la suite Recrutement 2018 – votre carrière dans la Data

MS Experiences 2017 – REX Power BI
Une nouvelle semaine, un nouvel article sur mes sessions à MS Experiences. Cette fois-ci, c'est un retour sur la session que j'ai pu animer sur Power BI. Cette session est en fait un retour d'expérience d'un projet que j'ai mené avec notre client Edenred. Comment le contrôle de gestion améliore le pilotage de l’entreprise avec…Lire la suite MS Experiences 2017 – REX Power BI

MS Experiences 2017 – le projet IronSkipper
J'annonçais quelques articles sur mon blog pour mes sessions de MS Experiences 2017, et finalement, c'est sur le blog AZEO que j'ai décidé de poster. Alors je cross-post ici un petit teaser pour la première session, pour vous donner envie d'aller y faire un tour. La session porte le nom de code en interne de…Lire la suite MS Experiences 2017 – le projet IronSkipper

Bien configurer le composant visuel KPI
L'astuce du jour concerne le composant visuel KPI que l'on retrouve nativement dans Power BI. Ce visuel permet d'afficher la valeur d'un KPI en fonction d'un objectif et, en arrière-plan, la tendance de cette même KPI. Dans l'exemple ci-dessous, on affiche la dernière valeur de la KPI (%) MoM Messages sur l'axe Mois ainsi que…Lire la suite Bien configurer le composant visuel KPI
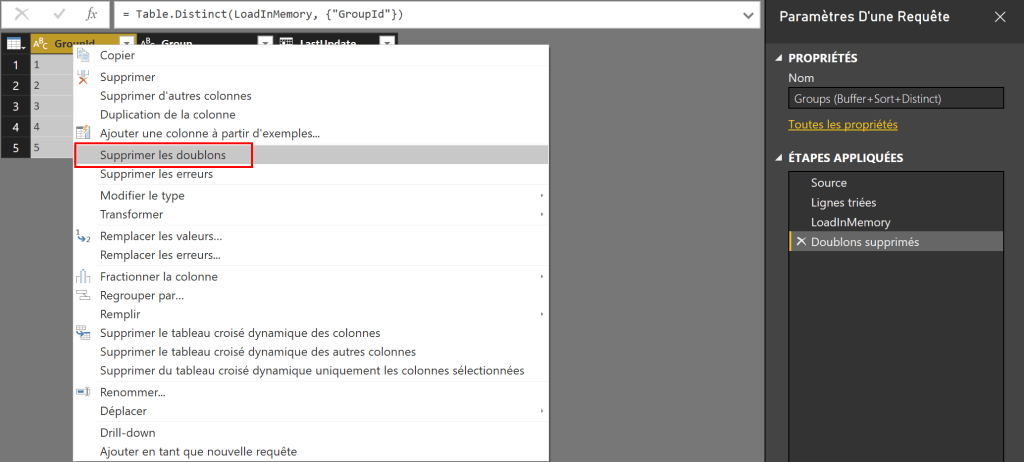
Dédoublonnage & dimension de type 1 avec Power BI, récupérer la ligne la plus récente
Il arrive que votre source de données contiennent des doublons. 2 lignes représentant la même chose mais avec une petite différence, qui vous empêche d'appliquer la transformation "Supprimer les doublons" (ie. Table.Distinct() ). Dimension de type 1 La cas d'usage typique est une dimension de Type I (au sens Kimball, cf. https://en.wikipedia.org/wiki/Slowly_changing_dimension#Type_1:_overwrite). Prenons l'exemple d'une table…Lire la suite Dédoublonnage & dimension de type 1 avec Power BI, récupérer la ligne la plus récente
MS Expériences 2017, une belle conférence
MS Experiences 2017 est maintenant terminée et quelle aventure. C'est ma 10ème participation à la conférence annuelle organisée par Microsoft (auparavant les TechDays) https://experiences17.microsoft.fr/ J'aime vraiment cette conférence, quel que soit son format. On y retrouve tout notre écosystème : partenaires, MVP, Microsoftees, clients, communautés… Depuis 10 ans, j'ai la chance d'y être conférencier. Cette…Lire la suite MS Expériences 2017, une belle conférence

Slides et retour sur le Global Azure Bootcamp Paris 2017
Le Global Azure Bootcamp, c'est une conférence sur les technologies Azure qui a lieu le même jour dans de très nombreuses villes autour du monde. Il est organisé par les communautés locales. En France, c'est AZUG FR qui est aux commandes avec, pour la 5ème édition, l'organisation de l'événement dans 6 villes : Paris, Lyon,…Lire la suite Slides et retour sur le Global Azure Bootcamp Paris 2017
Mise à jour d’un classeur Power Pivot depuis Excel 2010
Problématique A la mise à jour d’un classeur Excel contenant un modèle Power Pivot, dans certains cas on obtient ce message d’erreur : Une exception de type 'Microsoft.AnalysisServices.BackEnd.PQDataSourceAnnotationByPPException' a été levée. Cas de reproduction Cette erreur arrive quand le modèle Power Pivot utilise directement une connexion Power Query du classeur. Cette façon de faire est…Lire la suite Mise à jour d’un classeur Power Pivot depuis Excel 2010
