
Il arrive que votre source de données contiennent des doublons. 2 lignes représentant la même chose mais avec une petite différence, qui vous empêche d’appliquer la transformation « Supprimer les doublons » (ie. Table.Distinct() ).
Dimension de type 1
La cas d’usage typique est une dimension de Type I (au sens Kimball, cf. https://en.wikipedia.org/wiki/Slowly_changing_dimension#Type_1:_overwrite).
Prenons l’exemple d’une table Groupe dans laquelle le nom du groupe peut changer dans le temps. On ne souhaite garder que la dernière valeur.

Comme pour la dimension de Type 2 (cf. SCD avec Power BI), il nous faut une clé ainsi qu’un autre critère qui définit la dernière valeur, ie. la dernière ligne, celle que l’on doit garder
Méthode 1 : la jointure
Le principe que l’on va utiliser est de faire une auto-jointure sur la table, avec un regroupement par l’identifiant de ligne.
On commence par référencer notre requête de base et on applique un GROUP BY qui récupère ce qui va être le second critère de la clé (ie. de la sélection). Ici, on prend la date maximale car on veut la dernière valeur en date.
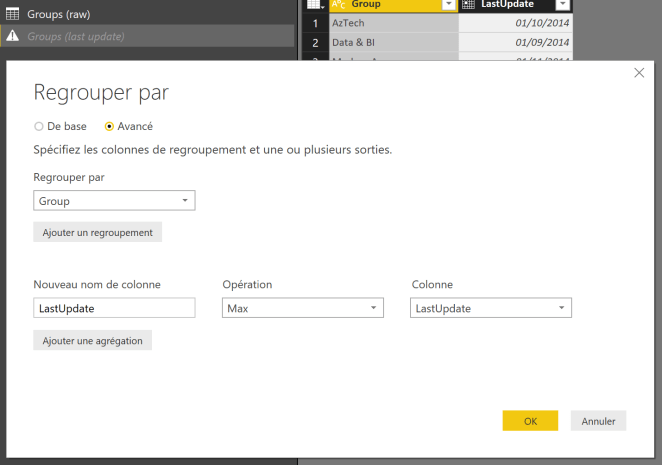
Ensuite, on référence une seconde fois notre requête de base et on aaplique une jointure (Fusionner les requêtes) avec la requête précédente sur la double clé (ici GroupId et LastUpdate).

La jointure est interne (INNER JOIN) car on veut justement filtrer sur la bonne ligne.
Cela nous donne 3 requêtes pour arriver au résultat final (on ne charge que la dernière évidemment).

On peut tout mettre dans la même requête M mais il faudra le faire manuellement.
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("…", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type text) meta [Serialized.Text = true]) in type table [GroupId = _t, Group = _t, LastUpdate = _t])
LastUpdate = Table.Group(Source, {"GroupId"}, {{"LastUpdate", each List.Max([LastUpdate]), type date}}),
JointureAvecLastUpdate = Table.NestedJoin(Source,{"GroupId", "LastUpdate"}, LastUpdate, {"GroupId", "LastUpdate"},"LastUpdateJoin",JoinKind.Inner),
SuppressionColonneInutile = Table.RemoveColumns(JointureAvecLastUpdate, {"LastUpdateJoin"})
in
SuppressionColonneInutile
Méthode 2 : SORT + DISTINCT
Le problème avec la fonctionnalité « Supprimer les doublons » appliquée sur la colonne de clé, c’est qu’elle garde bien une seule ligne mais le choix est arbitraire. En fait, la fonction Table.Distinct ne garde que la première ligne qu’il trouve.
Alors, on pourrait se dire qu’il suffit d’ordonner la table selon le second critère et le tour est joué.
Mais quand on manipule de la donnée depuis un moment, on sait que les fonctions de SORT et les jeux de données ne sont pas bons amis.
Et surtout, il se peut que vous ayez des résultats incohérents en fonction de votre source.
La faute au Query Folding, sorte d’optimiseur de requête, qui peut décider de faire le tri après le DISTINCT.
Heureusement, il y a une option dans le langage M (Power Query) pour contraindre l’optimiseur de requête : la fonction Table.Buffer()
Table.Buffer permet de mettre un résultat intermédiaire en mémoire et donc de forcer l’exécution à une étape particulière. En faisant : SORT + BUFFER + DISTINCT, on force l’ordre des étapes et notre technique fonctionne.
let
Source = #"Groups (raw)",
#"Lignes triées" = Table.Sort(Source,{{"GroupId",Order.Ascending},{"LastUpdate", Order.Descending}}),
LoadInMemory = Table.Buffer( #"Lignes triées" ),
#"Doublons supprimés" = Table.Distinct(LoadInMemory, {"GroupId"})
in
#"Doublons supprimés"
Attention : la contrainte est que le jeu de données doit tenir en mémoire, c’est le principe. Mais en règle générale, si vous êtes dans Power BI, vous êtes plutôt en mode self-service et je ne pense pas que vous récupériez tout votre Data Warehouse.
–
