
Ouch... J'en vois enfin le bout. 5 mois d'organisation du MS Cloud Summit, très intense vers la fin. Puis plus d'un mois pour dépiler tous mes sujets Business. Je sors enfin la tête de l'eau. Enfin…Pour ceux qui me connaissent, c'est pour repartir sur de nouveaux challenges. Mais ce n'est pas le sujet de ce post.…Lire la suite Mon retour sur le MS Cloud Summit

Savoir si un jour est férié en M (Power Query / Power BI)
Dans tous mes développements Power BI, il y a une table temps, une dimension calendrier. Je ne vous rappelle pas l'importance de cette table dans les calculs temporels en DAX. Générer cette table automatiquement est maintenant possible en DAX avec les fonctions CALENDAR et CALENDARAUTO(). Je vous passe également les multiples exemples que vous pourrez…Lire la suite Savoir si un jour est férié en M (Power Query / Power BI)

Sessions Data Science au MS Cloud Summit
Normalement, je n'ai pas à vous présenter le MS Cloud Summit. Vous savez déjà que c'est la grande conférence communautaire que le GUSS organise avec aOS, AZUG FR, Agile.NET et CMD. On y retrouve ce qu'aurait pu être les Journées SQL Server 2016 avec plein de sessions Data pour parler de la plate-forme de données…Lire la suite Sessions Data Science au MS Cloud Summit

Slowly Changing Dimension avec Power BI (et jointure sur une inégalité)
Les SCD (dimensions à variation lente ou tout simplement dimension de type 2 dans un espace Kimballien) sont un grand classique en BI. Du fait que Power BI soit sur un modèle de Annule-Remplace, il est difficile d'implémenter ce type de dimension. D'autant plus que la gestion des Surrogate Keys n'est pas native non plus.…Lire la suite Slowly Changing Dimension avec Power BI (et jointure sur une inégalité)

Rafraîchissement des données et Gateways Power BI à Madrid
(Je vous rassure tout de suite, le Data Refresh ne va pas plus vite en Espagne 😁) J'ai eu la chance d'être sélectionné comme Speaker au SQLSaturday de Madrid au mois de septembre. J'y ai présenté une session sur le rafraîchissement des données dans le service Power BI et notamment le rafraîchissement hybride via une…Lire la suite Rafraîchissement des données et Gateways Power BI à Madrid
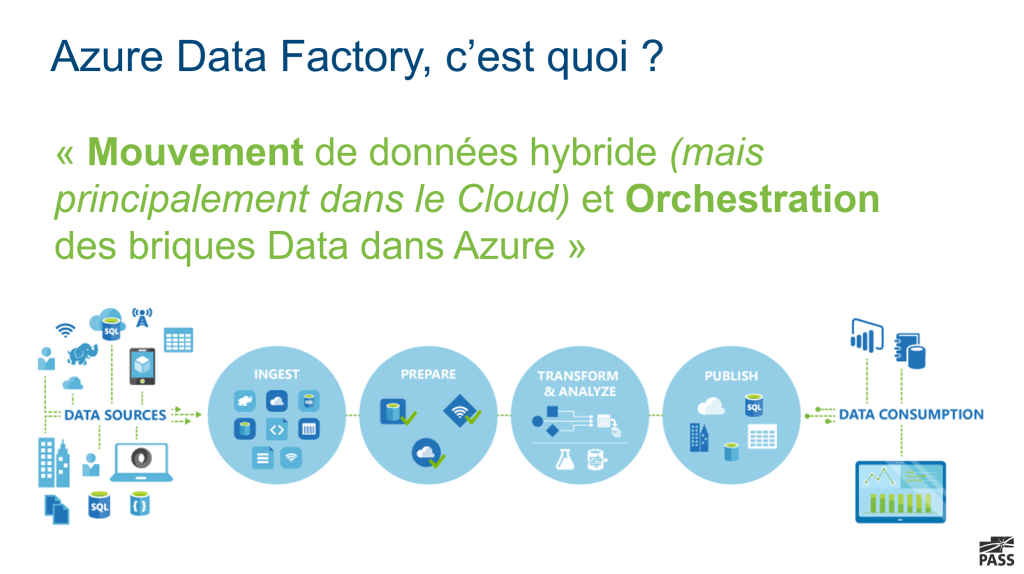
24HOP : Azure Data Factory, Mouvement de données hybride
J'ai parlé dans un précédent article du 24HOP => c'est ici ! J'y ai présenté une session sur Azure Data Factory Azure Data Factory, c'est un de mes produits préférés sur la Data Platform Azure. Cette session se veut technique mais reste toutefois sur un niveau découverte de l'outil. Si vous ne deviez retenir qu'une…Lire la suite 24HOP : Azure Data Factory, Mouvement de données hybride

24HOP, Partage et Collaboration avec Power BI
J'ai parlé dans un précédent article du 24HOP => c'est ici ! J'y ai présenté une session sur Power BI Partage et Collaboration avec Power BI Power BI offre de nombreuses solutions pour travailler à plusieurs sur un modèle, un rapport ou un tableau de bord. Cette session passe en revue les fonctionnalités de partage…Lire la suite 24HOP, Partage et Collaboration avec Power BI

24HOP, habituez vous à ce nom
24HOP veut dire 24 Hours of PASS. C'est un format de conférence 100% en ligne et le principe est simple, on aligne 24 sessions sur les 24 heures de la journée. Les 24HOP organisés sont principalement internationaux et donc on trouve des speakers et des participants dans chaque fuseau horaire. Évidemment, pas besoin de faire…Lire la suite 24HOP, habituez vous à ce nom
Retrospective Data / Communauté 2016
Comment démarrer cet article ??? Je me sens un peu honteux de ne pas avoir posté sur mon blog depuis des lustres... Et ce n'est pas parce que je n'ai rien à dire, c'est juste que je manque de temps. Et c'est d'autant plus frustrant quand on voit le nombre impressionnant de nouveautés, de news…Lire la suite Retrospective Data / Communauté 2016
Version DMV de sp_lock
Un post rapide pour partager un script T-SQL qui me sert à connaitre les ressources lockées par un processus dans SQL Server. La version old school est l'utilisation de la procédure stockée système sp_lock. Le problème, c'est qu'on ne peut pas faire de jointures avec d'autres tables systèmes, ni mettre de clause WHERE. Heureusement,…Lire la suite Version DMV de sp_lock
